Written by Nermin Karapandžić, Software Developer Softray Solutions

Java 21’s most exciting feature is virtual threads, promising near-optimal hardware utilization without the complexity of reactive programming. This post explores whether virtual threads can make asynchronous programming obsolete and introduces two complementary features: Structured Concurrency and Scoped Values.
Virtual threads are incredibly lightweight, enabling a new Structured Concurrency API that simplifies asynchronous programming. Introduced as a preview feature in JDK 19 and finalized in JDK 21, these threads allow a “thread-per-request” style with unprecedented scalability.
Structured Concurrency treats related tasks across different threads as a single work unit, improving error handling, cancellation, and system observability. Meanwhile, Scoped Values provide a more intuitive and efficient way to share immutable data across methods and child threads, offering performance advantages over traditional ThreadLocal variables.
If you only want an answer to the question, the answer is YES, virtual threads are making the reactive programming model irrelevant. If you want to know how and why then keep reading.
About being irrelevant
Virtual threads and reactive programming are about solving the same problem. Reactive programming has been there for 10+ years and we know how it works.
Virtual threads + structured concurrency is not there yet fully, structured concurrency is still in preview and might change.
Concurrency is hard, but it is needed to achieve higher performance (throughput), and until now, the paradigm to achieve higher throughput was callback-based / reactive programming, which comes with drawbacks.
Why do we need reactive programming, let’s see an example:
var image = someService.readImages();
var links = someService.readLinks();
var page = new Page(image, links);
This is a very simple example of a code that would be fine 20+ years ago, but is not fine in these times.
If we imagine these service calls are making requests across the internet, we could assume they would both take around 200ms; this is the time these calls will block our thread, making our CPU do nothing.
The old solution:
ExecutorService es = …
var f1 = es.submit(someService:readImages);
var f2 = es.submit(someService:readLinks);
var page = new Page(f1.get(1, TimeUnit.SECONDS), f2.get(1, TimeUnit.SECONDS));
You have an executor service, which is a pool of threads. You submit a callable and you get a future for both images and links which makes the two requests run in parallel instead of one after another.
What is wrong with this code?
It blocks threads
var f1 = es.submit(someService:readImages); -> ES thread is blocked
var f2 = es.submit(someService:readLinks); -> ES thread is blocked
var page = new Page(f1.get(1, TimeUnit.SECONDS), f2.get(1, TimeUnit.SECONDS)); -> Main thread is blocked
Blocking a platform thread is wrong for many reasons. But this is not the only issue, there is another sneaky issue.
It can lead to a loose thread
if f1.get(1, TimeUnit.SECONDS) crashes, the f2.get(1, TimeUnit.SECONDS) is never called, and now you have a loose thread. This means your executor service will now have a thread that will never be freed.
So you spend a lot of time fine-tuning, you realize the perfect amount of threads in the pool is 16 and you let your application run. After a day, you notice there are some performance issues; something’s not right; it’s like there are only 15 threads working, and after 3 days, it’s only 9 threads running… So what do you do? You restart the application, because there’s absolutely no way you can know what these threads are doing. And guess what happens after 3 days? Same thing.
It is hard to debug
This has to do with stack traces, we’ll see examples of this later.
What is a platform thread
A java.lang.Thread is a wrapper on a kernel (platform) thread.
It needs
- ~1ms to start
- 2mb of memory to store it’s stack
- context switching costs ~0.1ms
You can only have several thousands of them
This means that in a “one thread per request” model, we would be limited to this number of concurrent requests.
The reactive programming model improves this significantly because it uses one thread to handle multiple requests. It works by using non-blocking lambdas, which are fed into the framework and the framework wires the lambdas; i.e. it takes an output of the lambda and makes it the input of the next lambda.
For the same example, where we could have several thousands of concurrent requests with a “one thread per request” model, we could have up to a million concurrent requests with a reactive model.
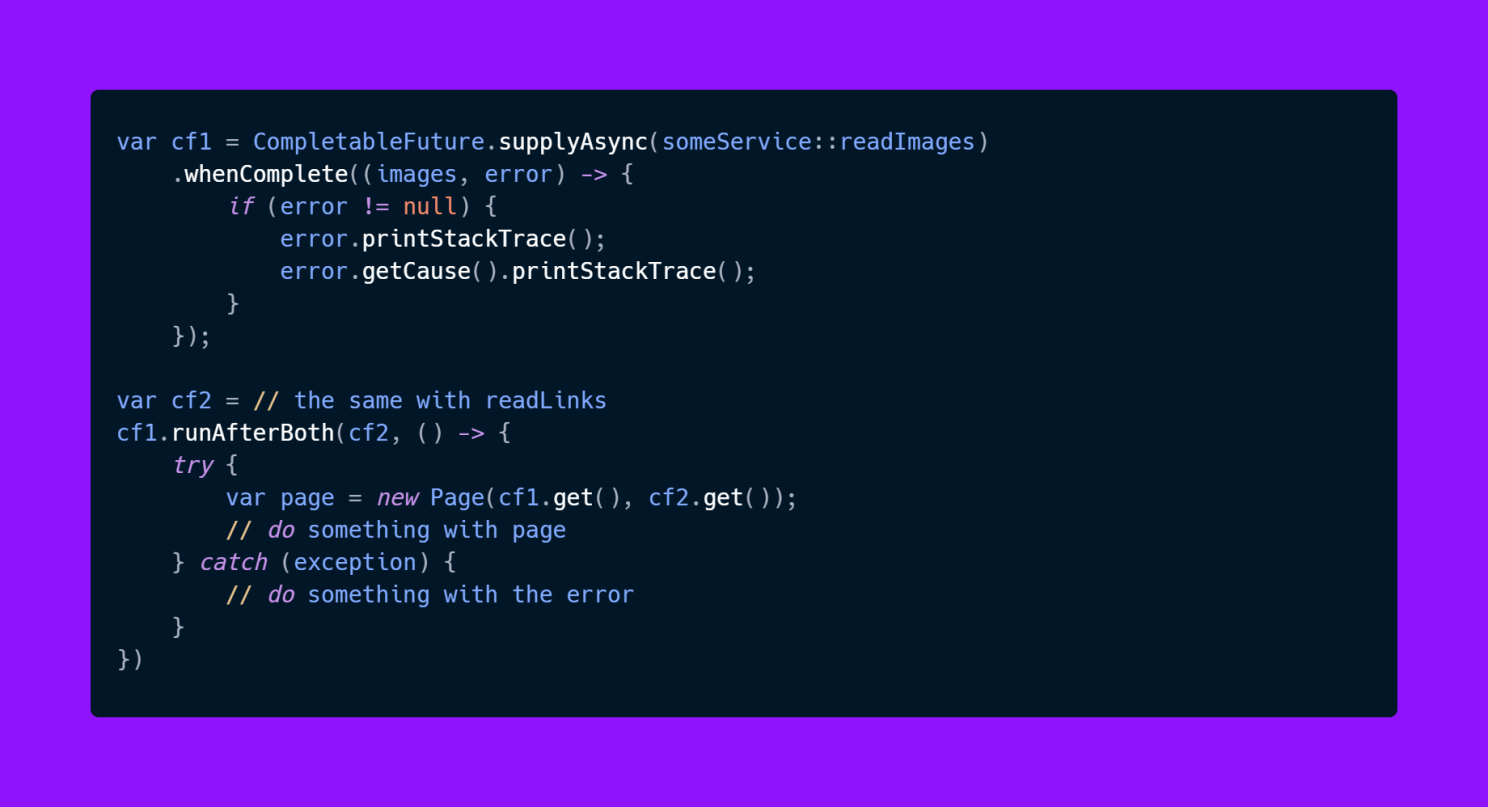
Let’s see one way we could rewrite the code in a reactive style.
var cf1 = CompletableFuture
.supplyAsync(someService::readImages)
.whenComplete((images, error) -> {
if (error != null) {
// do something
}
});
var cf2 = //…same for links
var cf3 = cf1.runAfterBoth(cf2, () -> {
var page = new Page(cf1.get(), cf2.get());
// do something with page
});
In this example the cf1.get() and cf2.get() are not blocking code, because it’s called when both futures are finished already.
The someService::readImages call is also not blocking because the reactive framework handles this in the background, an OS signal will be triggered that will tell the framework it can call the .whenComplete method.
But you can see by comparing the previous example that this is much more verbose and harder to understand and this is a very simple example.
And this is the price of reactive programming, you write code that is hard to write, hard to read and hard to maintain in the long run. The benefit of this code is that it will keep our platform threads busy at all times because we never block the thread, which means the thread can take more work and run it asynchronously in the same way.
What about debugging?
Let’s consider this example:
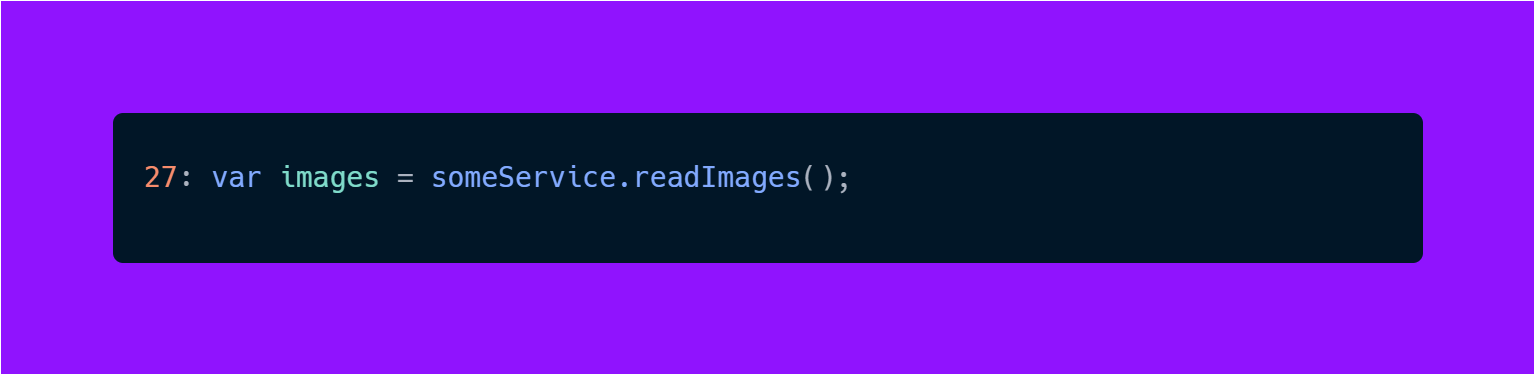
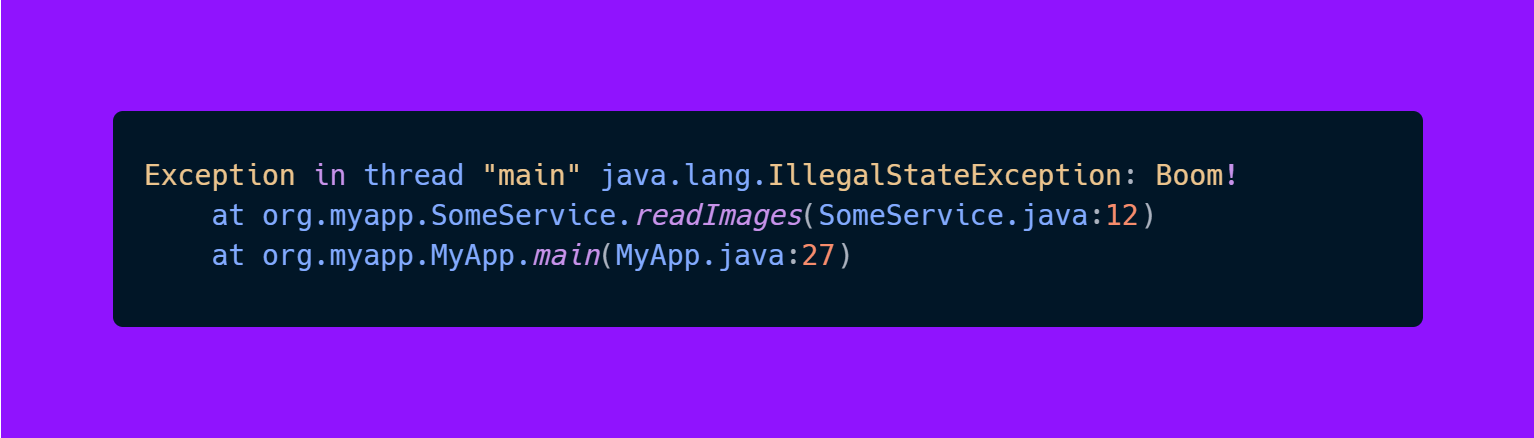
This stack trace is nice because it tells us exactly where the exception happened and what exception it was.
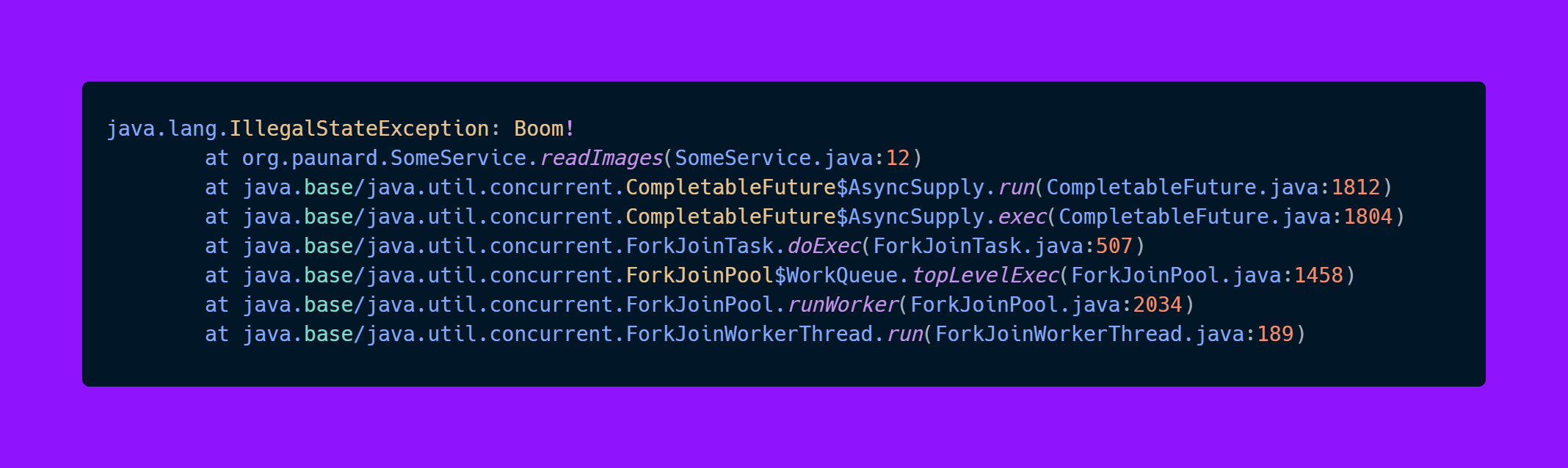
Now let’s see an example using executor service:
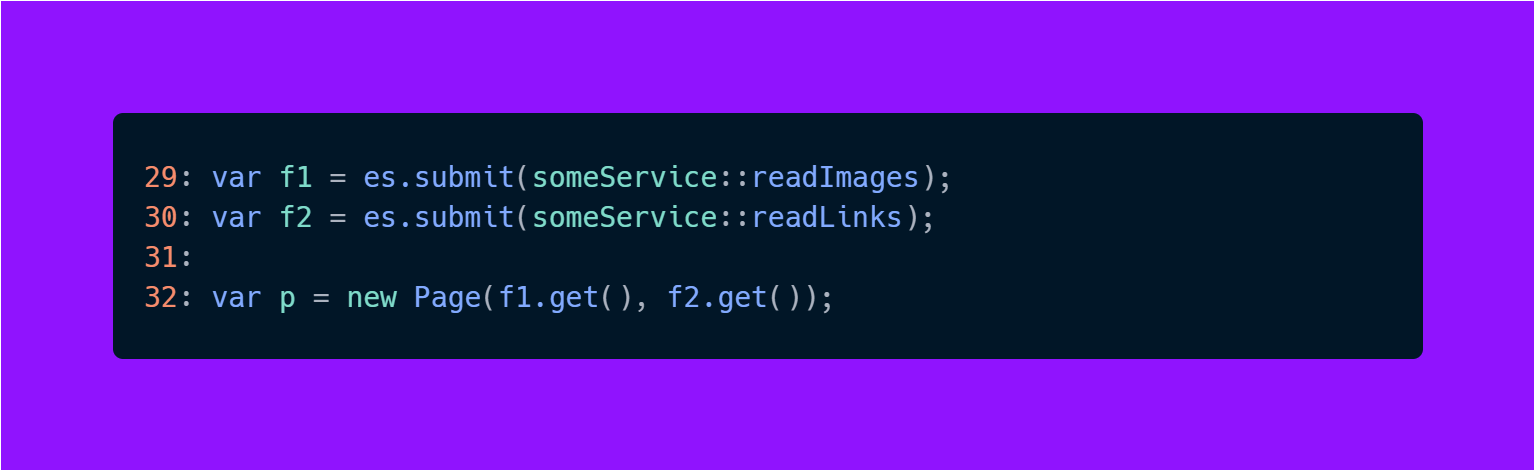
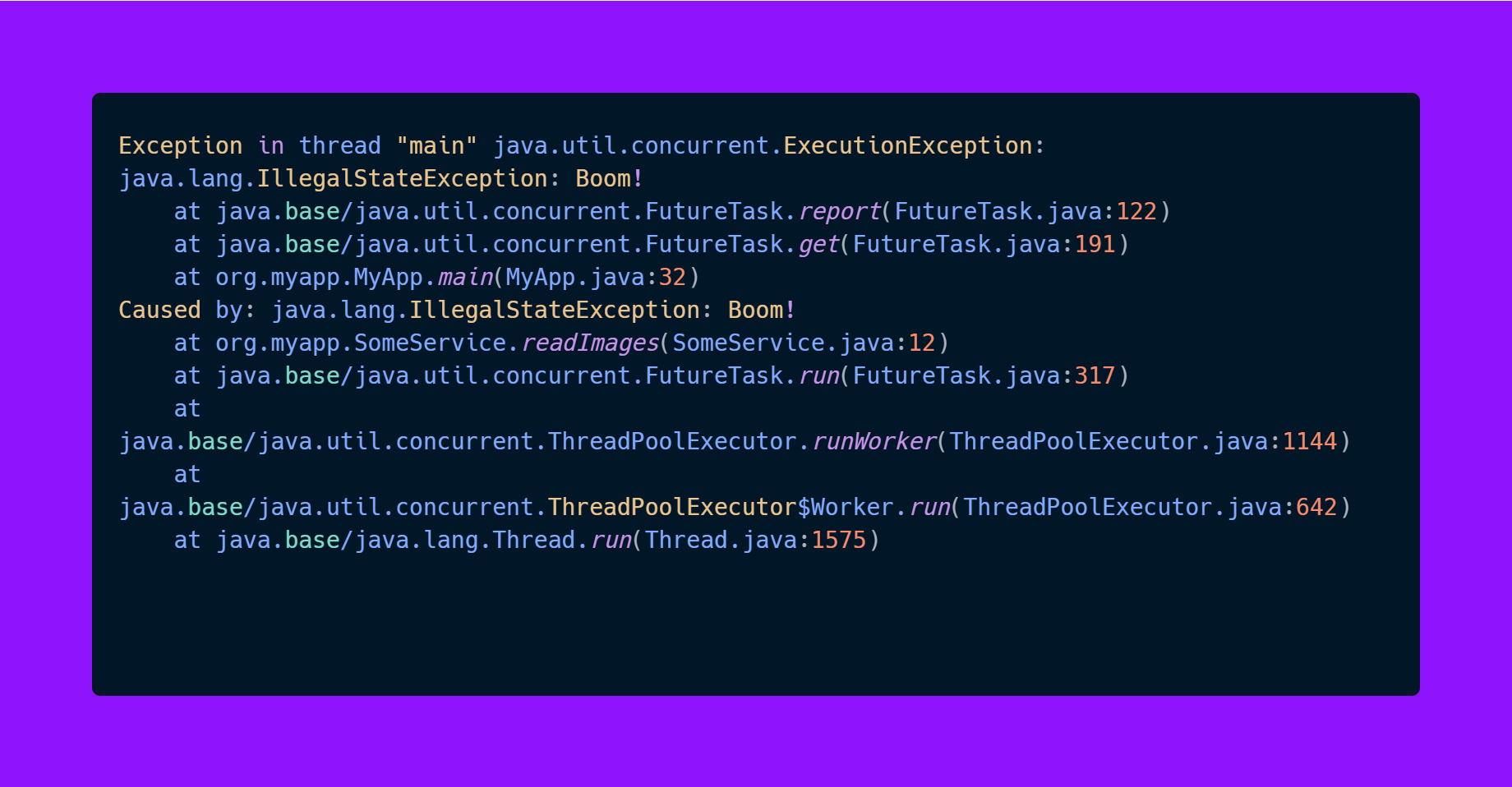
Here we see 2 exceptions in stack trace, one tells us the exception happened on line 32 when we called FutureTask.get, and below we see that this was actually caused by an exception that happened in SomeService.readImages..
And suppose you work in a larger project, when you see this exception, you would use your IDE to check where the SomeService.readImages is called from, but this could be from 100 places, and you cannot know exactly from which one it was called.
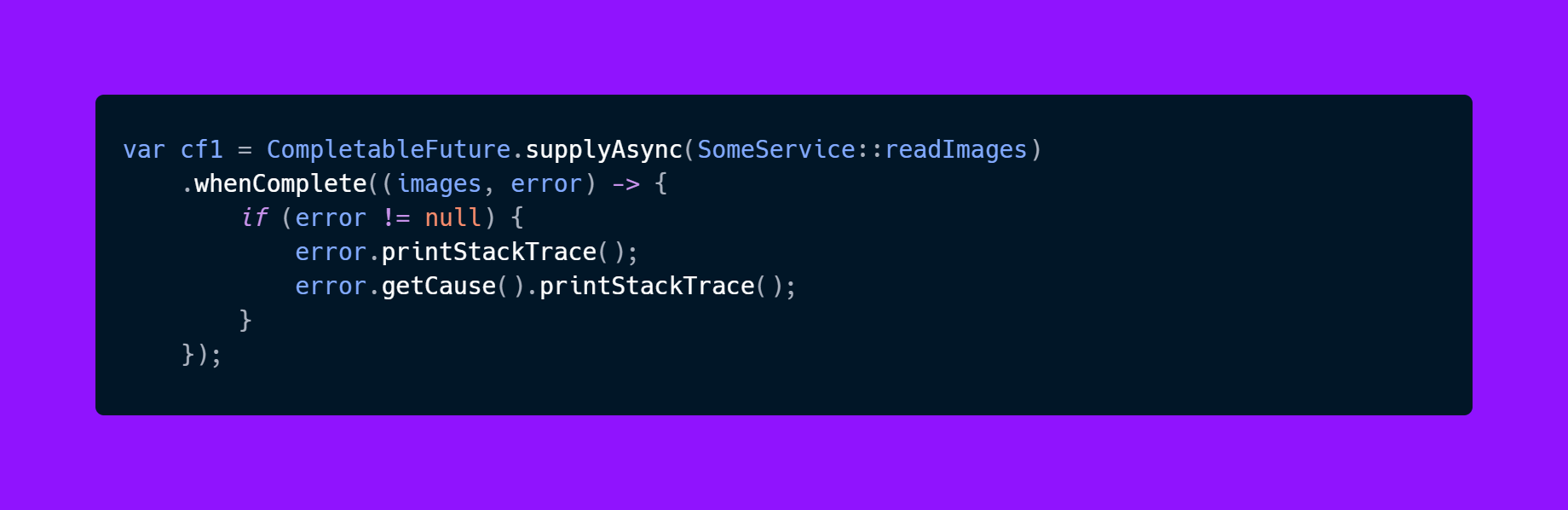
Let’s see an example with reactive pattern:
Suppose something goes wrong in SomeService.readImages; this is going to be the first stack trace
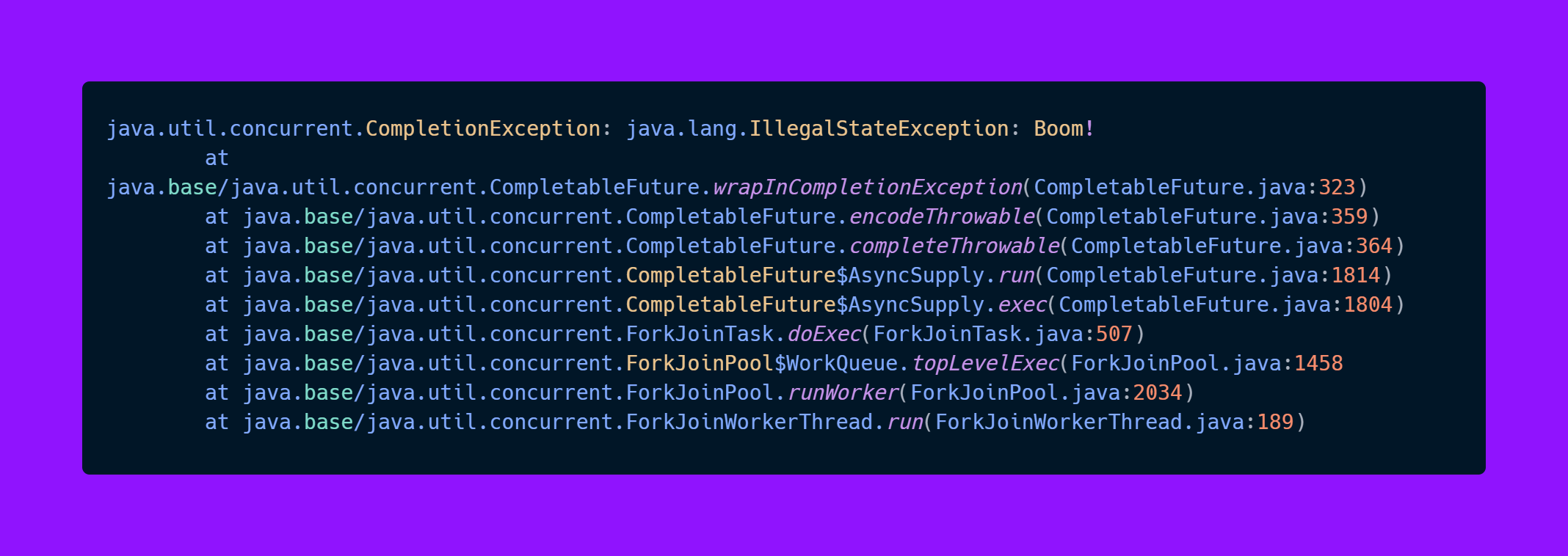
You only see the calls from the CompletableFuture api and only the message is from the actual service call.
But this is what the cause stack trace is showing
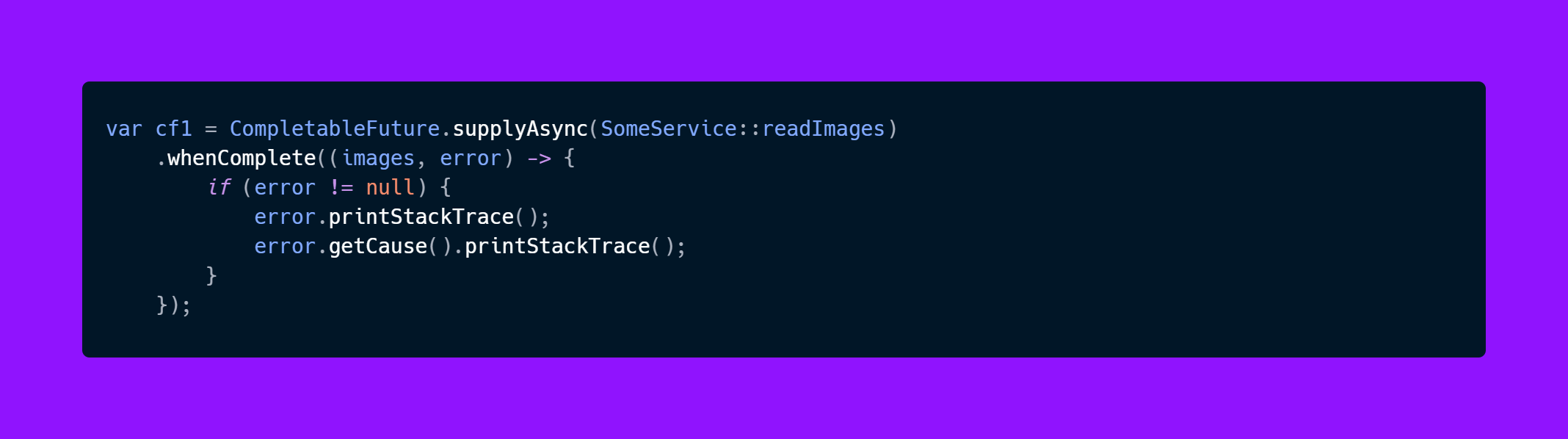
In the previous pattern we at least had the information that the exception happened when we called f1.get(), because we were calling this, it was our code, but in the completable future api you don’t have anything, because we’re not the ones invoking this code. We only know that something went wrong in readImages and you have no clue who called this method.
So to summarize, reactive programming is:
- efficient
- hard to write
- hard to read
- hard to test
- impossible to debug
- impossible to profile
So the ideal solution would be to have the simplicity of the one thread per request model and the efficiency of the reactive programming model. This is exactly what project loom is trying to achieve.
Introducing virtual threads
How do virtual threads work?
A virtual thread runs on a carrier thread (platform), and you cannot avoid that because the platform thread is the only way you have to run things in parallel on the OS.
At the core of it, there is a special thread pool, fork join pool, this is the second fork join pool on the jvm, the first one being the common fork join pool used to run parallel streams.
The virtual thread is mounted on a platform thread from the fork-join pull, it has its stack trace and everything, but it’s still running on top of a platform thread.
But there is a special kind of logic inside the api, that will use the hidden object in the jvm called continuation which will move the stack trace of the virtual thread from the platform thread it is mounted on to the heap as soon as the virtual thread is blocked. Now this platform thread is available to run other virtual threads. The continuation registers a signal that will trigger when the blocking operation is done, and at this point the virtual thread is returned to a free platform thread.
This makes writing blocking code in virtual threads ok, and not just ok but desirable.
So, compared to reactive programming, it is much easier because we don’t have to worry about blocking because blocking the virtual thread will never block a platform thread. While in reactive programming we have to make sure never to block as it might block the platform thread (which might be serving multiple requests, so we’re essentially blocking multiple requests)
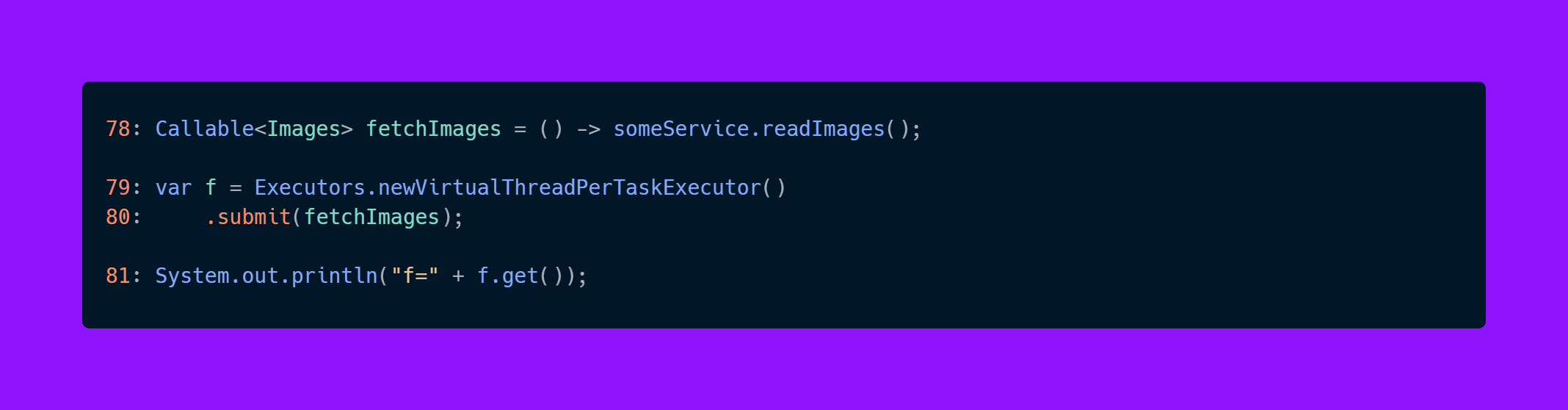
This is what code with virtual threads looks like:
Callable<Images> fetchImages = () -> someService.fetchImages();
var f = Executors.newVirtualThreadPerTaskExecutor()
.submit(fetchImages);
System.out.println("f = " + f.get());
and if something goes wrong:
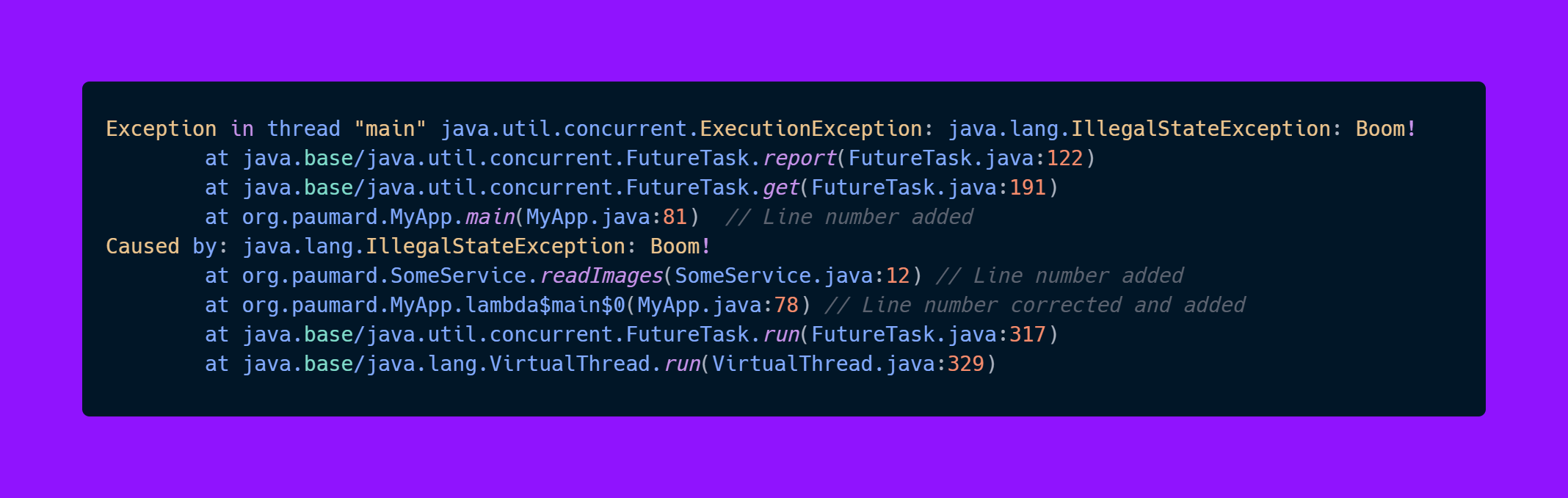
We see where the exception happened and who was the caller.
In previous examples, we had 2 requests that we wanted to run in parallel, and we can do it with this approach of creating a new virtual thread and then calling the get at the end for both tasks, but there is an even better approach.
try (var scope = new StructuredTaskScope<>()) {
var imagesSubtask = scope.fork(() -> someService.readImages());
var linksSubtask = scope.fork(() -> someService.readImages());
scope.join();
var page = new Page(imagesSubtask.get(), linksSubtask.get());
} catch (InterruptedException e) {
// Handle exception
}
This is using the new structured concurrency API.
If something goes wrong in readImages
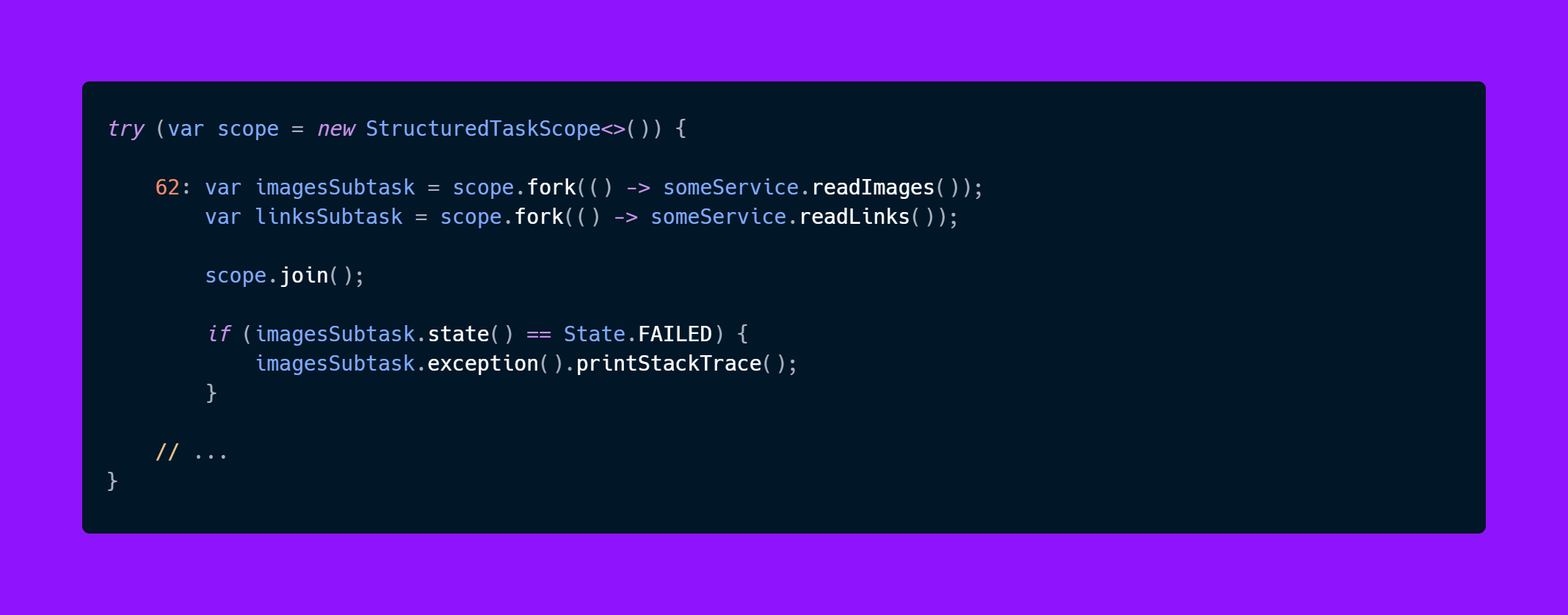
We can check the state of the task and we can get the exception stack trace.
And this is the exception that you get

This tells you exactly from where the service was called and where it failed.
So this fixes all the problems we mentioned before:
- Blocking platform thread is bad
- Blocking virtual thread is ok, it never blocks platform thread
- Having a non-relevant stack trace is annoying
- Fixed, your stack trace tells you exactly where the call happened
- Having loose threads is hard to fix
- No more loose threads because with AutoCloseable all resources will be cleaned up when using structured concurrency with try with resources.
Virtual threads
- Are as efficient as reactive models
- Provide a simple programming model (good old imperative model)
- Make debugging possible and easy
- Make profiling possible
ThreadLocal and ScopedValue
ThreadLocal
These variables differ from their normal counterparts in that each thread that accesses one (via its get or set method) has its own, independently initialized copy of the variable. ThreadLocal instances are typically private static fields in classes that wish to associate state with a thread (e.g., a user ID or Transaction ID).
What is wrong with ThreadLocal
- they are mutable
- the VM cannot optimize them
- they may be kept alive forever
- …
Virtual threads support ThreadLocal variables.
ScopedValue is a model that is supposed to replace ThreadLocal
- they are not mutable
- they are not bound to a particular thread
- they are bound to a single method call
Consider the following example with a scoped value USERNAME that is bound to the value “duke” for the execution, by a thread, of a run method that invokes doSomething().
private static final ScopedValue<String> USERNAME = ScopedValue.newInstance();
ScopedValue.where(USERNAME, “duke”, () -> doSomething());
Inheritance
ScopedValue supports sharing data across threads. This sharing is limited to structured cases where child threads are started and terminated within the bounded period of execution by a parent thread. More specifically, when using a Structured Task Scope, scoped value bindings are captured when creating aStructuredTaskScopeand inherited by all threads started in that scope with the fork method.
In the following example, the ScopedValue USERNAME is bound to the value “duke” for the execution of a runnable operation. The code in the run method creates a StructuredTaskScope and forks three child threads. Code executed directly or indirectly by these threads running childTask1(), childTask2(), and childTask3() will read the value “duke”.
private static final ScopedValue<String> USERNAME = ScopedValue.newInstance();
ScopedValue.where(USERNAME, "duke", () -> {
try (var scope = new StructuredTaskScope<String>()) {
scope.fork(() -> childTask1());
scope.fork(() -> childTask2());
scope.fork(() -> childTask3());
...
}
});
Conclusion:
Virtual threads and structured concurrency fix the problems of reactive / asynchronous programming without giving up performance.
ScopedValue fixes the problems of ThreadLocal variables.